Planning And Building An Open Source End-to-End Data Plattform
Presenting my findings, learning and advice on how to realize an End-to-End platform - open source, reproducable.
Planning And Building An Open Source End-to-End Data Plattform
Introduction:
My project for summer of bitcoin 2025: ln-history, has multiple facets:
-
Running End-to-End-Plaform, featuring:
- Core-Lightning plugin to publish gossip messages
- Real-time gossip management
- Bulk import of gossip
- Optimized database for a variety of queries
- (UI-) Clients
-
Plug-And-Play-like docker containers for others to use
- Clean documentation to reproduce my work
- Import of different gossip storage formats
This blog article presents my findings, learnings and advice on how to realize this.
Challenges: Engineering a solution for a problem that has not been fully understood.
Although I had spent time crafting my application for summer of bitcoin where I spent time thinking about building the ln-history platform, I can say in retro perspective that I did not fully understand the problems I was facing. In complex software projects this happens and the rise of agile project management shows that there are effective solutions to this.
When building ln-history, I was working on multiple components simultaniously. If the data a component sends changes, every component that consumes that data needs to be modified as well. During the development process this created a cascade of work.
My advice is that you should not start developing right away but also you should not think about the problem too long. Some challenges will arise during development that are unforeseeable (unfortunately).
The sweet spot lies somewhere in between. At the end of this article I will come back to this.
Requirements
Only start developing when the requirements are 100% certain. In case they are not, you do not have enough understanding of the problem.
Defining the requirements is harder than it might sounds at the beginning. There are always details to think about which could have a big impact on the platform.
The four requirements of the platform are:
- Get a snapshot (in raw gossip format ->
bytes) of the Lightning Network at a given timestamp - Get the difference between two snapshots (in raw gossip format ->
bytes) for a given start and a given end timestamp - Get all gossip (->
bytes) bynode_id - Get all gossip (->
bytes) byscid
Two examples from the process of defining the requirements of the ln-history platform.
-
I created the last two requirements, although they where not part of the official project description for summer of bitcoin, but I consider them as very useful. This decision influenced the the database schema design heavily.
-
Another important detail is the format in which the snapshots, or node/channel information gets returned by the platform. Initially I tried to parse the data right away, creating more problems than solving. Deciding in the requirements that the format of the result is the raw gossip foramt in
bytesinfluenced almost every component of the platform.
My advice is that the requirements should be as concrete as possible. I would never start a project with a vague requirement a la "Have a database to perform analytical queries about Lightning Network gossip".
Architecture
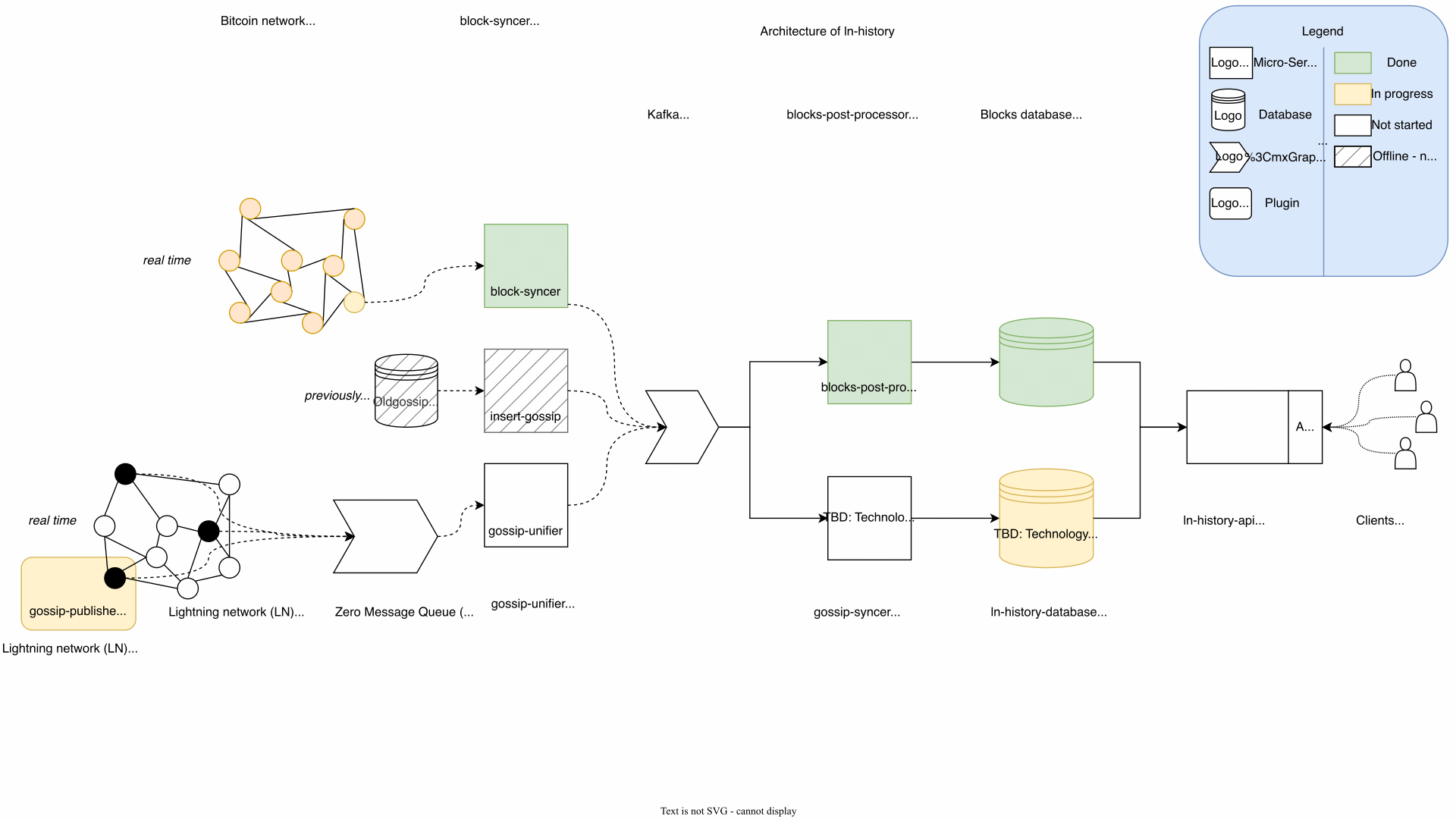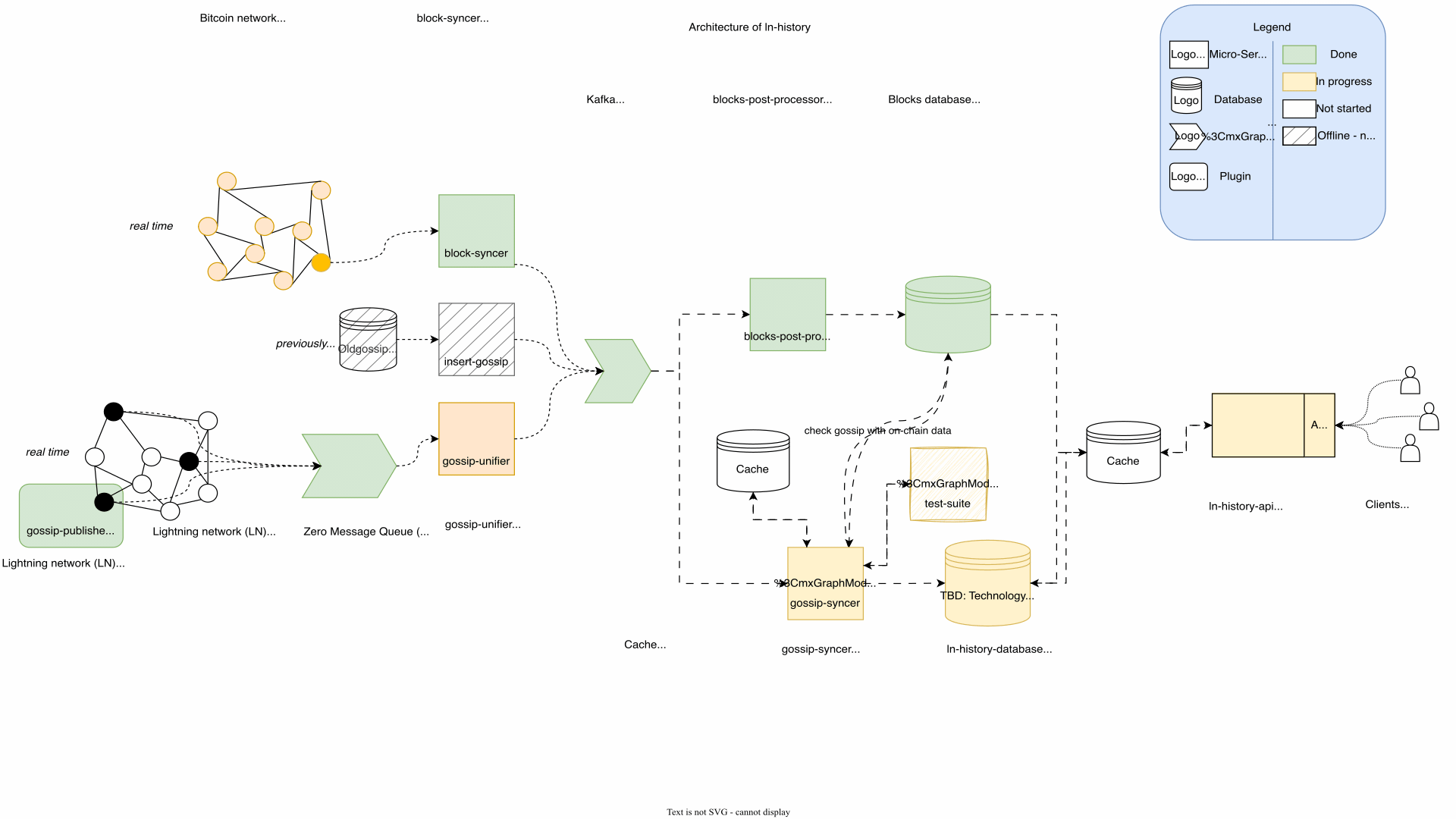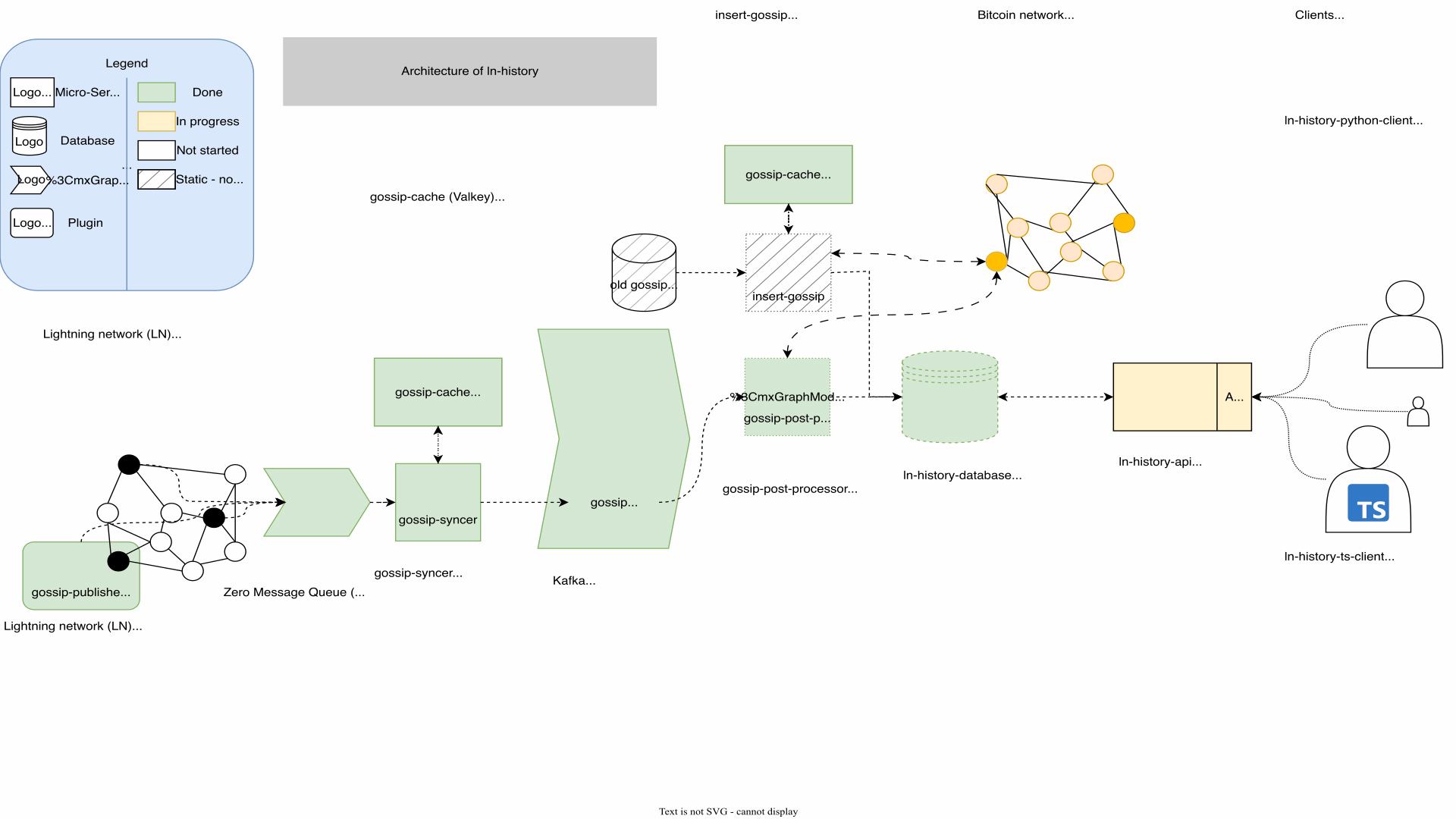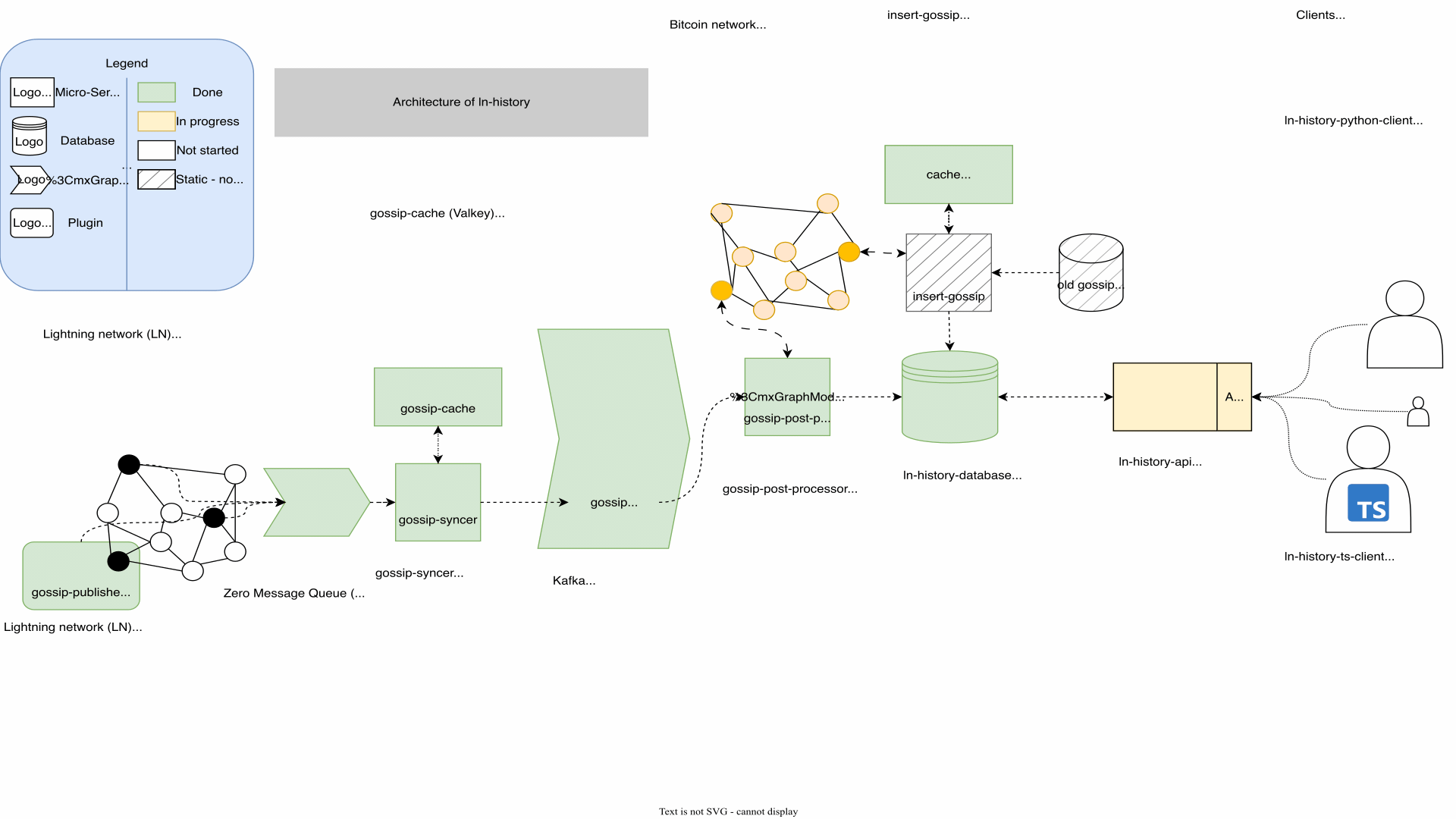
Architecture is the art of anticipating which changes will be costly in the future.
I once heard this quote (that was the ghist) by an lead architect. This fairly short definition really stuck to me.
There are many facets to consider when in comes down to designing the architecture of a platform:
- Extensability (modularity, reusablity, time it takes for new developers to contribute (context of open source))
- Performance (latency, throughput)
- Security (privacy)
- Persistence (redundance, backup)
- Time (parallelizing work)
- Vendor-lock-in (dependencies)
- ...
For my ln-history platform I used a micro-service architecture of dockered python projects together with Kafka. Following the seperation of concerns paradigm I was able to narrow the problems down and keep the code easy to maintain and extend. The cost of this decision was, that changes to the interfaces of the micro services created work on multiple components. It also forced me to keep track of every component which started to become their own projects to manage.
I think the GIF speaks for itself: I updated the architecture countless times. Suprisingly, I deleted more components than added. Every architectural change was a result of me understanding the problem better.
My advice is to relax and take your time when designing the architecture. Having a good architecture can save an increadible amount of work later. Investing at this step pays off. I explained the architecture to my mentor René as well as to friends with no background. While explaining I found cleaner solutions. Letting them ask questions can create a lot of clarity. At the end you as the developer benefit the most from a clean architecture, since every development and testing step becomes easier.
Two easy tips:
- A very useful tool for this is the open source software draw.io.
- Do you see lines crossing each other in your diagram? If yes: try to reorder components. If some lines still cross: Your architecture could very likely be improved.
Project management
"Hyper" management: Tickets, Milestones etc. vs no management at all: Finding the sweet spot when working alone
Two realities clash: As soon as a project is getting complex managing it can enable you to get so much more done, especially reducing to do the same work twice.
Doing classic SCRUM but only with yourself feels and sounds ridiculous. But some concepts of SCRUM make so much sense and I would highly recommend them doing:
- At the beginning of the day, take a few minutes and think about which tasks are the most important. Having an overview over the work that needs to be done is very helpful.
- Having regular calls with someone (like my mentor) that has technical and "management" knowledge. There will be difficult problems and decisions necessary on how to solve them, where a (technical) discussion gets you so much closer to your goal.
Be humble: It is very unlikely that you will do everything by yourself correctly.
Development
The core of the ln-history project was to develop and actually implement the services. Besides all the other mentioned "adminastrative" topics mentioned, I was able to extend my knowledge about software development so much! Here are some points that I find worthy to touch.
From PoC to Production
I build the micro services in a way that I first built a Proof-of-Concept (PoC), meaning that the requirement of that micro service is actually working. If this was possible I went over to "upgrade" this version to be "production-level".
I like this way of working and follow the 80 / 20 - principle. The PoC of the micro services could be set up quickly and if they were not able to work as expected, I can change them without losing too much.
When to abstract and when to concretize
While developing this question popped up countless times. Abstrcting something has a high initial cost but can longterm save a lot. Nonetheless abstracting something can be very distracting, to a point where you forget/stop working on the task you were working before. This can be mitigated by clever managing your work, but it gets significatly more difficult if you have not fully grasped your problem and are still in the phase of testing and building PoCs. In those cases I would, although this might not align with "mainstream coding guidelines", recommend to just build something working. I spent quite a lot of time abstracting things that I could delete at the end because I found another approach to solve it.
Technology
Working on ln-history made one (obvious) thing very clear to me: Utilizing technologies (of any kind: frameworks, database-systems, messaging-broker, etc.) all use the same hardware at the end of the day. If you have a complex problem - in this case storing the gossip messages efficiently - you need to actually think about how the hardware is being used. Technologies provide beautiful abstractions, interfaces and much more, but this often comes with an costly overhead.
There won't be a technology that you can simply "import" and that solves your problem. Also certain technologies with their benchmark, even if they don't have any bad intend, should be understood with a grain of salt. When working with challeging problems, falling for the "marketing-claims" happens easily. I was underwhelmed when testing out other database technologies.
My advise specifically when looking at databases: Use a widespread "multi-use" technogly and fine tune it for your problem. See this article for details.
Usefulness and uselessness of clean code
Clean code has many advantages but can cost a lot of time. Before making the code 100% clean, it’s better to stop at 90% and keep building — even if it’s open source and you feel unhappy knowing you could do better. Using automatic linting, prettifiers, or formatters to check your code quality is often unnecessary early on, since frequent changes make those corrections obsolete until the code has proven itself in production.
During development I spent a good amount of time cleaning up and perfectionizing the code, which made me tired and even stopped me from committing regularly. In retrospect, I should have been more bold.
René showed me this inspiring article Be Bold.
Logging
Especially when your software is running in production, logs are extremly valuable. I can recommend, that every logged message should try to include a value of a variable.
When trying to reconstruct why the software broke, those information are invaluable.
It might take some time, but this is a habit your future self will appretiate.
This simple python function can be used in your code and creates a clean scaffholding for your logs:
import os
from logging import Logger, getLogger, INFO, Formatter, StreamHandler
from logging.handlers import RotatingFileHandler
def setup_logging(log_dir: str = "logs", log_file: str = "logs.log") -> Logger:
os.makedirs(log_dir, exist_ok=True)
logger = getLogger("logger")
logger.setLevel(INFO)
log_path = os.path.join(log_dir, log_file)
file_handler = RotatingFileHandler(log_path, maxBytes=5_000_000, backupCount=100)
file_handler.setFormatter(Formatter("%(asctime)s - %(levelname)s - %(threadName)s: %(message)s"))
stream_handler = StreamHandler()
stream_handler.setFormatter(Formatter("%(asctime)s - %(levelname)s - %(threadName)s: %(message)s"))
logger.addHandler(file_handler)
logger.addHandler(stream_handler)
return logger
Using AI
I might update this section
While working on ln-history I have countless examples where those models: Claude, ChatGPT 4o and ChatGTP 5 failed. I sometimes spend many minutes crafting a prompt in the hope they would resolve it.
On the other hand there have been situations where those models hit the nail on the head. Getting the solution that 'just works' for a rather complex problem in seconds is the dream.
Currently I am more of a fan of doing it yourself without AI. It is more like a personized stackoverflow, but not a replacement for software development as a whole. The context of my platform was most times just way too much for it to understand it and giving a summarized context takes time writing the prompt that might not even produce a valuable result.
From a "fun" perspective I really like to think and develop the code by myself. When errors appear, I can spot them quickly and fix them. Debugging and fixing code from a LLM is painful.
On the other hand I realized that it takes less "brain power" if you work a whole day constantly requesting the LLM instead of purly doing it yourself. I might be able to create more output in a day when using a LLM than doing it myself. But when looking on a longer time-scale I guess that I am also learning and memorizing how the code is actually working much easier if I came up with it instead of a LLM. This way in the long run I am more leaning towards writing the code by yourself.
All the texts of the blog and the documentation have been written by myself without AI.
Documentation
When to write documentation?
Firstofall, it should be obvious that documenting your code is necessary and should be done, hence when not if.
I started to write the documentation close to the end of the project. In retro perspective I should have written it simultaneously with the development. As soon as I "upgraded" the components from "PoC" to "production-level". I could even recommend to write the documentation first and then "upgrade" the component to "production-level", much like the idea of Test-Driven-Development. It gives yourself an overview as well as something to see for "Product Owner" / supervisor.
A challenge I faced during the project: How to show progress, especially in the context of databases
I realized that documenting is a very good way to show progress. In specific when working with databases, where there is neither code nor text I recommend to list the queries and their EXPLAIN (ANALYZE) result and discuss the costs, indexes (maybe even clustering) etc. This approach is like documenting your analysis although you are just setting things up.
Hardware:
I did not put a lot of thought into the hardware I rent to run my services. In case you come from the software development "side" you might think everything is solvable with software, but at some point, investing in hardware is the only way to go. After upgrading from virtual cores to actual cores, I realized how big this detail is: The performance of everything jumped significantly.
Having a good developer experience not only makes the project more fun but also speeds up the development process.
I highly recommend to not save on this end. Sometimes your development time might be more scarce than the cost of better hardware.
Conclusion:
Unlike mathematics and other sciences, engineering on a solution in computer science is not exact and many (completely) different solutions can yield the same result. I am certain that with experience you develop a feeling in your gut with which you can decide much quicker and accurate which solutions bring you a result and which ones do not. This feeling (based on countless hours of expierience) guides you to the sweet spot I mentioned in the introduction.
I am happy with my participation and learnings at summer of Bitcoin 2025. Having the chance to discuss with René about a wide range of topics, gave me so many heureka moments where it made "click". I also gained confidence that I am able to create impactful software.